
Tavaly még elég volt a Google top 10-ben lenni. Ma a potenciális ügyfeled rákérdez a ChatGPT-re, a Claude-ra vagy a Perplexity-re, és vagy benne vagy az AI válaszában, vagy nem.
Ez egy új diszciplína. Nem SEO, nem content marketing – valami a kettő között. A neve AI citation optimalizálás (más néven GEO, LLM SEO, AEO), és 2026-ban ez a legérdekesebb kérdés: miért választja ki egy nyelvi modell pont ezt a forrást, és nem a másikat?
Ebben a cikkben konkrét, ma beállítható tényezőket mutatok, amelyeket a ChatGPT Search, a Perplexity, a Google AI Overviews és a Claude keresése figyelembe vesz. Nem sejtés, nem elméletgyártás: az elérhető keresési logokból és a platformok publikált dokumentációjából vezettem le a mintát.
Miben különbözik az AI citation a klasszikus SEO-tól
A Google a link-alapú rangsorolást finomította 25 évig. A találati lista célja, hogy kattints: te döntöd el, melyik oldal nyitja meg a választ.
Egy AI válasz másképp működik. A modell elolvassa 5-15 forrás szövegét, és egyetlen bekezdésbe sűríti őket. A kattintás opcionális – sokszor már a válaszban is ott van minden, amit tudni akartál.
Ebből három következmény jön:
- A szövegminőség számít, nem a link. Ha a modell nem érti egyértelműen, amit írsz, nem fog idézni.
- A struktúrának explicitnek kell lennie. A modell nem úgy olvas, mint az ember: a bekezdés elején keresi a lényeget.
- Kevesebb hely van. 10 kattintható találat helyett 3-5 idézett forrás fér egy válaszba. A küszöb magasabb.
Ez nem azt jelenti, hogy a klasszikus SEO stratégia elveszti az értelmét – az AI ugyanarra a tartalomra támaszkodik, amit a kereső indexelt. De a rangsorolási szempontok eltolódtak.
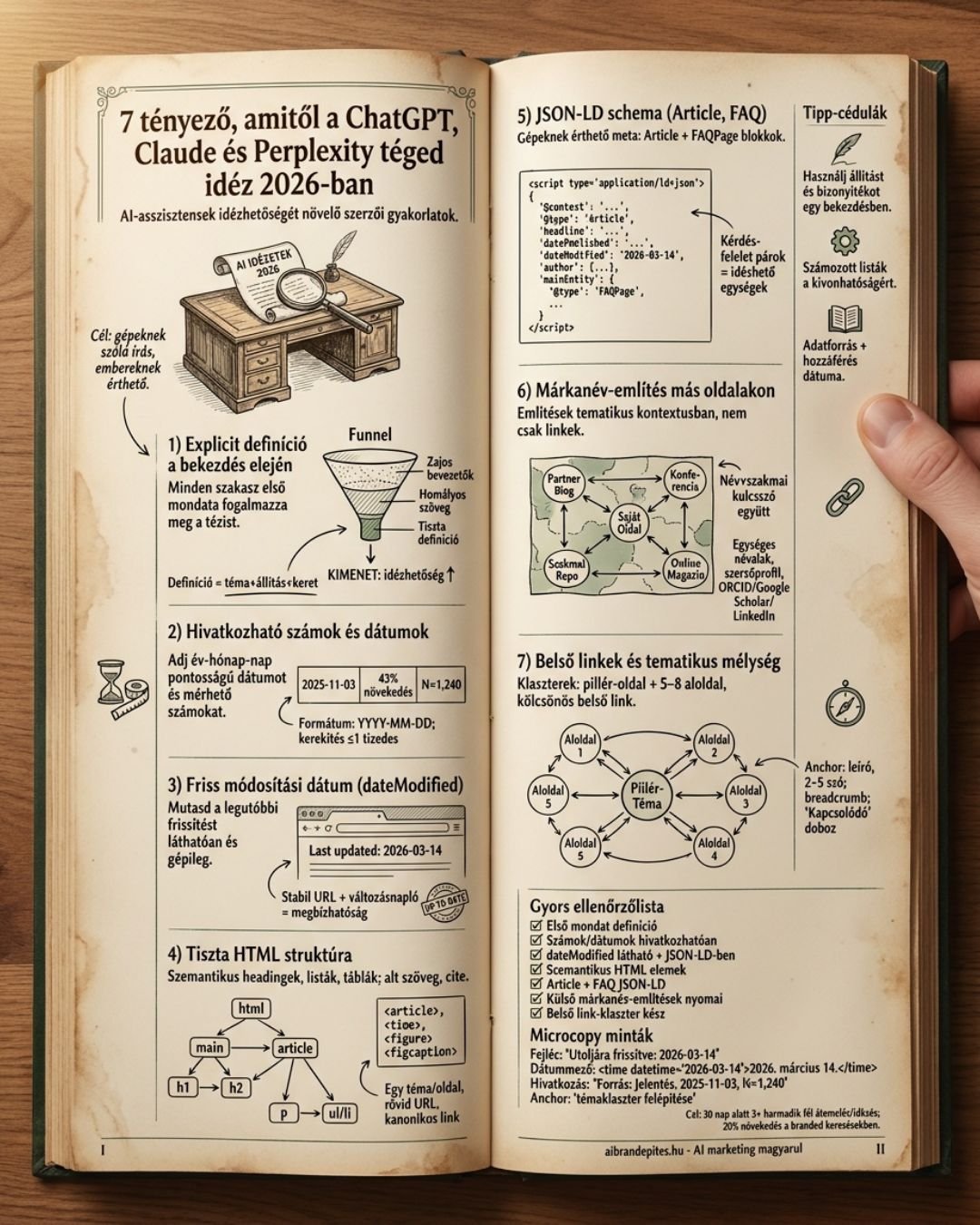
7 tényező, amit az AI modellek figyelembe vesznek
1. Explicit definíciók a szöveg elején
A modellek a bekezdés első 1-2 mondatából döntik el, hogy ez a szakasz releváns-e a kérdésre. Ha elrejted a lényeget a 4. bekezdésbe, nagy az esély, hogy a modell átugorja.
Rossz: «Amikor 2017-ben elkezdtem marketinggel foglalkozni, még senki nem beszélt attribúcióról. Azóta sok minden változott, és ma már egyértelmű, hogy...»
Jó: «Az attribúció azt a folyamatot jelenti, amikor egy ügyfél útját végigkövetjük az első érintkezéstől a vásárlásig.»
A második változatot az AI idézni fogja. Az elsőt nem.
2. Hivatkozható számok és dátumok
A modellek előszeretettel idéznek konkrét statisztikákat: százalékok, időpontok, árak, mérések. A «sokan gondolják» típusú állítások messze kerülnek a válaszból, mert nincs mit kiemelni.
Ha saját kutatást csinálsz, tedd a számot és a mérés dátumát a bekezdés elejére:
«2026 első negyedévében a 4.200 fős mintánkban 38% használt naponta ChatGPT-t.»
Ezt a mondatot 10x nagyobb eséllyel látod majd viszont egy AI válaszban, mint egy szöveges összefoglalót.
3. Friss dátum és frissítés jelzése
A ChatGPT Search és a Perplexity aktívan súlyozza a publikálási és módosítási dátumot. Egy 2022-es cikket egy friss, 2026-os mellett ritkán idéz, még ha a 2022-es jobb is.
Ha tartalmat frissítesz:
- Állítsd át a
dateModifiedmezőt a schema.org Article JSON-LD-ben - Tedd látható helyre: «Utolsó frissítés: 2026. április»
- Írd át ténylegesen a szöveget, ne csak a dátumot – a modellek ellenőrzik a tartalmi egyezést
4. Tiszta HTML struktúra
A modellek a nyers HTML-t olvassák, nem a rendered oldalt. Ami JavaScripttel töltődik be, azt sokszor nem látják.
Gyakorlati ellenőrző lista:
- H1 – H6 hierarchia logikus (ne ugrálj H1-ről H3-ra)
- A lényegi tartalom
<article>vagy<main>tag-en belül - Táblázatok valódi
<table>elemmel, nem div-ekkel - Listák
<ul>/<ol>-lal - Oldalszervezés: sidebar és footer távol a fő tartalomtól
Ha lazy-loadolod a tartalom felét, a crawler csak a felét látja.
5. Strukturált adat (JSON-LD schema)
A schema.org jelölés gépnek mondja el, hogy miről szól a szöveg. Egy jól kitöltött Article, FAQPage vagy HowTo schema megnöveli az idézés esélyét, mert a modell explicit kontextust kap.
Minimális csomag egy blogcikkhez:
- Article schema: headline, author (Person), datePublished, dateModified
- BreadcrumbList: kategória hierarchia
- FAQPage: ha van gyakran feltett kérdések szekció
- Author Person object: sameAs linkekkel LinkedInre, korábbi publikációkra – ez E-E-A-T szignál
Fontos: az author Person típusként erősebb szignál, mint az Organization. Egy konkrét embernek életrajza, LinkedIn-profilja, korábbi cikkei vannak – ezeket az AI összeköti.
6. Más forrásokban megjelenő márkanév
A modellek a training során asszociációkat tanulnak meg. Ha a márkanevedet 50 különböző magas minőségű szövegben együtt emlegetik egy témával, a modell ezt elmenti.
Kész, tesztelt promptok marketing, kódolás, kreatív írás és mindennapi feladatokhoz – letöltheted egy kattintással.
Ingyenes letöltés →Ez azt jelenti, hogy a digitális PR (vendégcikk, podcast megjelenés, idézés független szerzőknél) és a szakértői pozícionálás most kézzelfoghatóbb marketing ROI-t ad, mint korábban. Nem szeretnéd, hogy az AI keresésekor más cégek nevét dobja ki a tiéd helyett.
7. Belső linkek és tematikus mélység
Az egyedi cikknek nehéz önállóan idézési tekintélyt szereznie. A modellek azt keresik: ez a site egy téma szakértője, vagy random blog?
A válasz a site tematikus mélységéből jön:
- Van-e 10-30 cikked ugyanarról a témakörről?
- Logikusan linkelnek egymásra belső linkekkel?
- Létezik-e pillar page / főcikk, ami összefoglalja és a részletcikkekre mutat?
Egy 100 cikkes, jól hálózatos blog egy szűk témáról sokkal több AI citációt kap, mint egy 500 cikkes, mindenről szóló site.
Platform-specifikus tippek
A négy nagy platform ugyanazt a célt szolgálja, de más infrastruktúrán fut. Az alábbi táblázat összefoglalja, melyik mire épül, és hol érdemes ellenőrizned a láthatóságodat. A crawler nevét azért érdemes ismerned, mert a robots.txt fájlban pontosan ezeket engedélyezed vagy tiltod.
| Platform | Index forrása | Crawler (user-agent) | Hol ellenőrizd |
|---|---|---|---|
| ChatGPT Search | Bing index + OAI-SearchBot | OAI-SearchBot, GPTBot | Bing Webmaster Tools |
| Claude | Saját webkeresés | ClaudeBot, anthropic-ai | Szerver-logok, robots.txt |
| Perplexity | Saját crawl + élő web | PerplexityBot | Közvetlen kérdés-teszt |
| Google AI Overviews | Google index (passage-szint) | Googlebot | Search Console |
A leggyakoribb hiba: valaki évekkel ezelőtt letiltotta a GPTBot-ot egy «ne tanuljon a tartalmamból» megfontolásból, és most csodálkozik, miért nem idézi a ChatGPT. A tanuló crawler (GPTBot) és a kereső crawler (OAI-SearchBot) két külön dolog – ha láthatóságot akarsz, a keresőt mindenképp engedd be.
ChatGPT Search
A ChatGPT 2025 óta élőben keres a weben, ha a kérdés friss infót igényel. Indexe a Bing crawlerén alapul, tehát a Bing láthatóság itt többet számít, mint a Google ranking. Ellenőrizd a Bing Webmaster Toolsban, hogy a site-od egyáltalán indexelve van-e.
Claude
A Claude 2025 végén kapott web search funkciót. A feltételezett crawler a ClaudeBot és az anthropic-ai user-agent. Ha a robots.txt-ben blokkolod őket, Claude nem fogja látni az oldaladat.
Perplexity
A Perplexity a leginkább «citation-first» keresőmotor: minden válaszhoz 3-8 forrást rak ki. Itt a legnagyobb esély, hogy közvetlen forgalmat kapsz az idézésből. Crawler neve: PerplexityBot. A Perplexity használata cikkünkben a felhasználói oldalról is bemutatjuk, hogyan jelennek meg a források.
Google AI Overviews
A Google saját AI válaszai a klasszikus Google indexből jönnek, de új rangsorolási szignálok kerültek hozzá. A legfontosabb: a «passage-level» relevancia. Már nem az egész oldal számít, hanem az a konkrét bekezdés, amely leginkább illik a kérdésre. Egy 2000 szavas cikkedből lehet, hogy egyetlen bekezdést emel ki.
Mit ne csinálj
Van néhány taktika, amely rövid távon jól hangzik, de hosszú távon hiteltelenít:
- AI-val generált sablonos cikk 500 darabszámban. A modellek felismerik a saját outputjukat. A haladó promptolás még nem elég önmagában; a belerakott saját tapasztalat számít.
- Kulcsszó stuffing. Nem működött 10 éve sem. Az AI modellek különösen érzékenyek a természetellenes nyelvre.
- Fekete-hat prompt injection a szövegbe. Volt egy fél év, amikor az emberek rejtett fehér szöveggel próbálták megmondani a modellnek, mit mondjon. A platformok azóta leszűrik, és reputáció-szinten is büntetik.
- Hamis dátumok. Ha «2026. április»-ot írsz egy 2023-as cikkre szöveges frissítés nélkül, a modellek összevetik a tartalmat és nem hisznek neked.
Egy 14 napos akcióterv
Ha most kezdesz hozzá, ebben a sorrendben érdemes haladnod:
- 1-2. nap: Ellenőrizd, hogy a ChatGPT, Claude, Perplexity crawlerek nincsenek-e blokkolva a robots.txt-ben.
- 3-4. nap: Audit a top 10 legforgalmasabb cikkeden: van-e schema, friss
dateModified, explicit első mondat. - 5-6. nap: Írd át a 3 legfontosabb cikk bevezetőjét úgy, hogy az első 2 mondatban ott legyen a definíció.
- 7-8. nap: Adj hozzá
FAQPageschemát 3 cikkhez, ahol gyakori kérdések megválaszolódnak. - 9-10. nap: Készíts egy pillar page-et a fő témádból, és linkeld a 10-15 legjobb részletcikket.
- 11-12. nap: Tesztelés: tedd fel a ChatGPT-nek, a Claude-nak és a Perplexity-nek azokat a kérdéseket, ahol elvileg téged kellene idéznie. Nézd meg, most kit idéz.
- 13-14. nap: Hozz létre egy
llms.txtfájlt a root könyvtárban, ami explicit listázza a legfontosabb cikkeidet.
Ez két hét. A mérhető változás 1-3 hónap múlva jön, de a munka legnehezebb részét az első két hétben teszed le.
Hogyan mérd, hogy idéz-e az AI
A klasszikus SEO-ban van Search Console, ami megmondja, hányadik helyen állsz. Az AI citation-nél nincs ilyen központi műszerfal – de három módszerrel mégis nyomon követheted.
1. Kézi kérdés-teszt
Írd össze azt a 10-15 kérdést, amire a tartalmaddal válaszolni szeretnél, és tedd fel mind a négy platformnak havonta egyszer. Jegyezd fel, kit idéz a modell. Ez primitív, de a leghitelesebb: pontosan azt látod, amit az ügyfeled is lát. Egy egyszerű táblázat elég hozzá: kérdés, dátum, idézett források, szerepelsz-e.
2. Hivatkozó forgalom a GA4-ben
Ha a Perplexity vagy a ChatGPT idéz és valaki rákattint, az forgalomként megjelenik. A Google Analytics 4-ben a forrás-közeg riportban keresd ezeket a hivatkozókat:
chatgpt.coméschat.openai.comperplexity.aiclaude.aigemini.google.com
Ez a forgalom kicsi, de erősen szándékvezérelt: aki innen jön, már elolvasta, hogy téged idézett a modell, és szándékosan kattintott tovább. Gyakran jobban konvertál, mint az organikus keresés.
3. Márkanév-említés figyelése
Sokszor a modell a nevedet említi link nélkül – ez nem ad kattintást, de épít. Havonta kérdezz rá közvetlenül: «Kik a vezető szakértők [a te témádban] Magyarországon?» vagy «Milyen eszközöket ajánlasz [a te területeden]?». Ha a neved megjelenik, jó úton jársz. Ha nem, tudod, min kell dolgoznod.
Az llms.txt fájl — konkrét példa
Az llms.txt egy egyszerű szöveges fájl a domain gyökerében (oldalad.hu/llms.txt), amely a nyelvi modelleknek listázza a legfontosabb tartalmaidat. 2026 áprilisában még nem szabvány, de egyre több site teszi ki, mert olcsó és alacsony rizikójú. Így néz ki egy minimális verzió:
# AI Brandépítés
> Magyar AI portál: modellek, appok, promptok, kódolás és digitális termékek, magyarul.
## Fő tartalmak
- [AI citation optimalizálás](https://oldalad.hu/blog/ai-citation-chatgpt-claude-idezes/): hogyan kerülj be az AI válaszaiba
- [AI SEO stratégia 2026](https://oldalad.hu/blog/ai-seo-strategia-2026/): a teljes keretrendszer
## Kapcsolat
- Email: hello@oldalad.hu
A logika ugyanaz, mint a robots.txt vagy a sitemap.xml esetében: nem kötelezed rá a modellt semmire, csak megkönnyíted a dolgát. Tedd ki, frissítsd, amikor új fontos cikk jelenik meg, és ennyi.
Összegzés
Az AI citation optimalizálás nem varázslat és nem külön diszciplína. Ugyanazok az alapelvek működnek, amelyeket a jó tartalom mindig is követett: egyértelmű szöveg, hiteles szerző, átlátható struktúra, frissen karbantartott információ.
Ami változott: a Google helyett most 3-4 AI platform is olvas, mindegyiknek saját logikája van, és a küszöb magasabb. A jó hír: ami a ChatGPT-nek jó, az a Claude-nak is, és az a valódi olvasónak is. Nincs konfliktus a platformok között.
A következő 12 hónapban ez a terület fog a legtöbbet változni. Érdemes most belekezdeni, amikor még nem mindenki gondolkozik róla.


